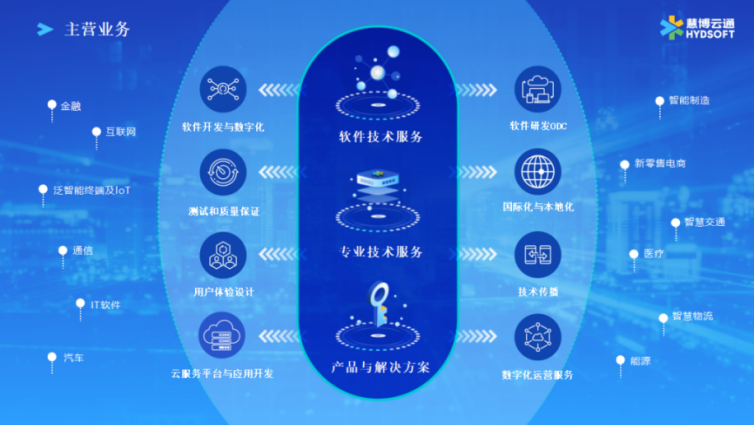
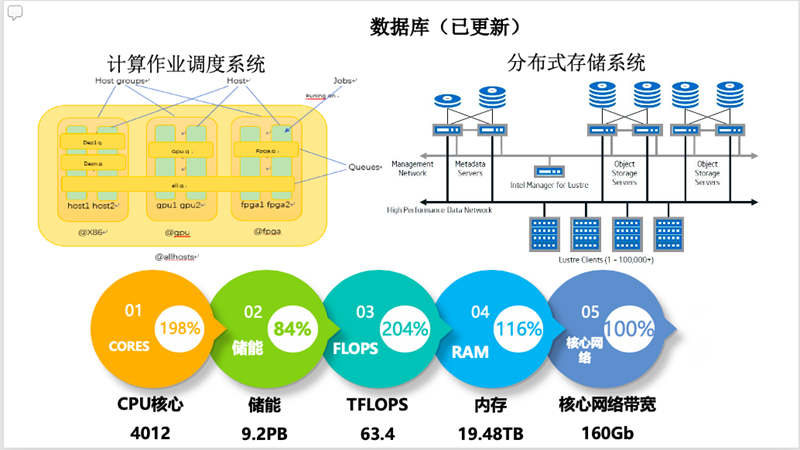
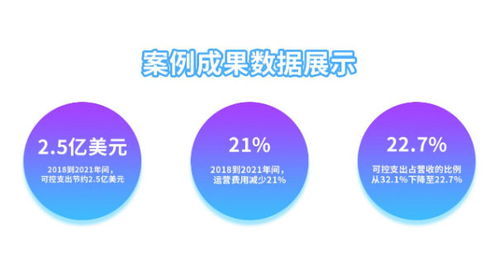
經營范圍:一般項目:網絡技術服務;信息技術咨詢服務;技術服務、技術開發、技術咨詢、技術交流、技術轉讓、技術推廣;會議及展覽服務;軟件開發;軟件銷售;廣告設計、代理;廣告制作(除依法須經批準的項目外,憑營業執照依法自主開展經營活動)許可項目:廣告發布(廣播電臺、電視臺、報刊出版單位)(依法須經批準的項目,經相關部門批準后方可開展經營活動,具體經營項目以相關部門批準文件或許可證件為準)
公司簡介: 武漢細云信息技術服務有限公司成立于2016年09月26日,注冊地位于武漢東湖新技術開發區鳳凰園一路2號普能產業園辦公樓及廠房辦公樓棟/單元1-6層/號5樓009室,法定代表人為周紅圖。經營范圍包括一般項目:網絡技術服務;信息技術咨詢服務;技術服務、技術開發、技術咨詢、技術交流、技術轉讓、技術推廣;會議及展覽服務;軟件開發;軟件銷售;廣告設計、代理;廣告制作(除依法須經批準的項目外,憑營業執照依法自主開展經營活動)許可項目:廣告發布(廣播電臺、電視臺、報刊出版單位)(依法須經批準的項目,經相關部門批準后方可開展經營活動,具體經營項目以相關部門批準文件或許可證件為準)
公司名稱:武漢細云信息技術服務有限公司
法人代表:周紅圖
注冊地址:武漢東湖新技術開發區鳳凰園一路2號普能產業園辦公樓及廠房辦公樓棟/單元1-6層/號5樓009室
所屬行業:軟件和信息技術服務業
更多行業:應用軟件開發,軟件開發,軟件和信息技術服務業,信息傳輸、軟件和信息技術服務業

電話:1776201**
郵箱:3658089**[email protected]
地址:武漢東湖新技術開發區鳳凰園一路2號普能產業園辦公樓及廠房辦公樓棟/單元1-6層/號5樓009室